
某天深夜,看到一组超好看的摄影笔记,手指条件反射地长按保存——结果满屏的水印糊了一脸。
行吧,那就自己动手研究一下。
这篇文章不放代码,纯聊思路——我是怎么一步步从 F12 里扒出小红书的数据结构,找到绕过水印的方法,最后做成一个能用的工具的。
1. 先观察:水印到底是怎么加上去的?
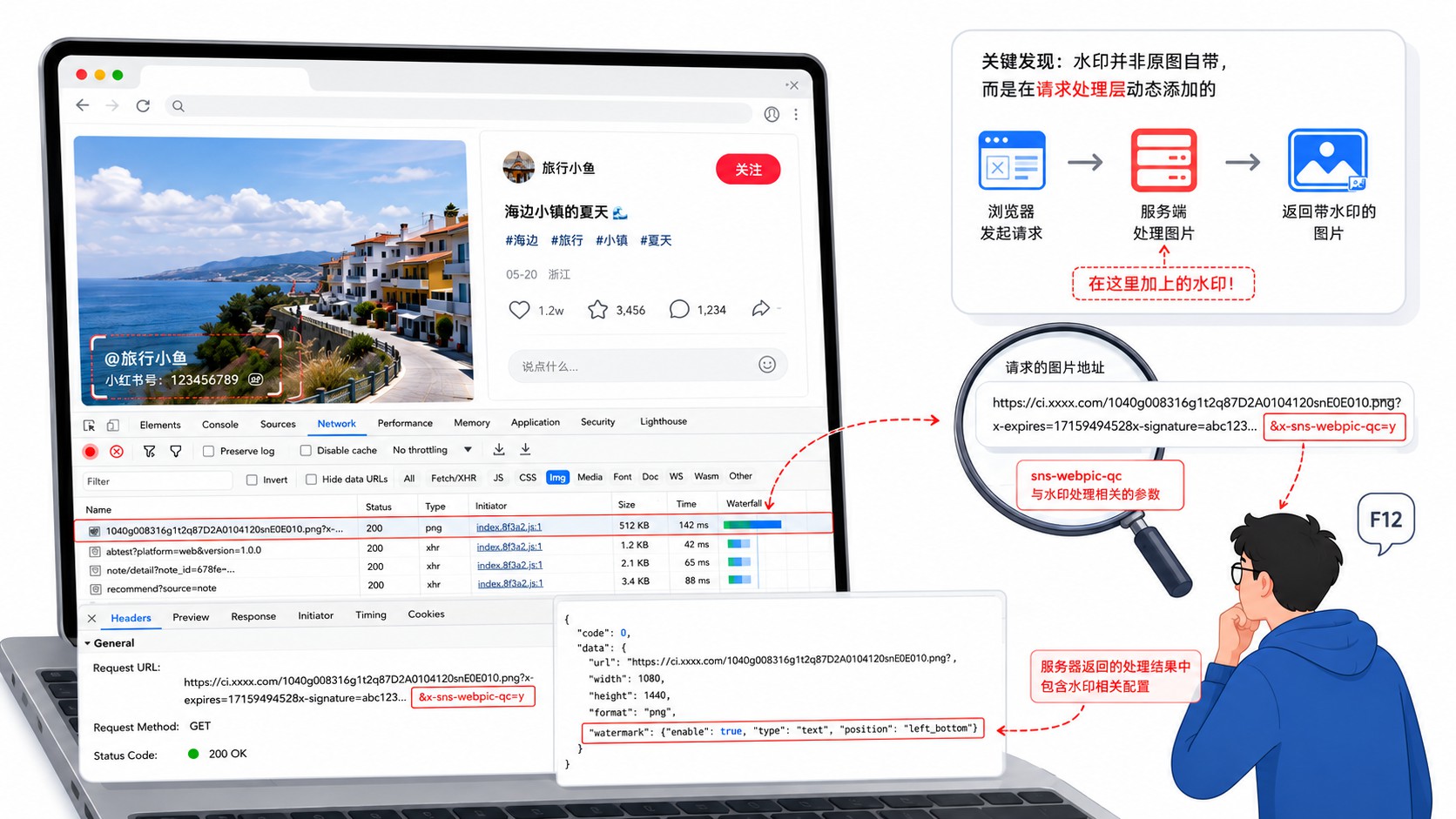
打开一篇小红书笔记,F12 → Network,随便点开一张图片的请求,看 URL:
https://sns-webpic-qc.xhscdn.com/xxxx
注意这个路径里的 sns-webpic-qc——qc 大概率是 quality control 的缩写,水印就是在这一层处理加上去的。也就是说,小红书的原图本身是没有水印的,水印是请求经过这个中间层时被动态叠加上去的。
那问题就变成了:有没有办法绕过这一层,直接拿到原图?
2. 翻数据:页面里藏了什么宝贝
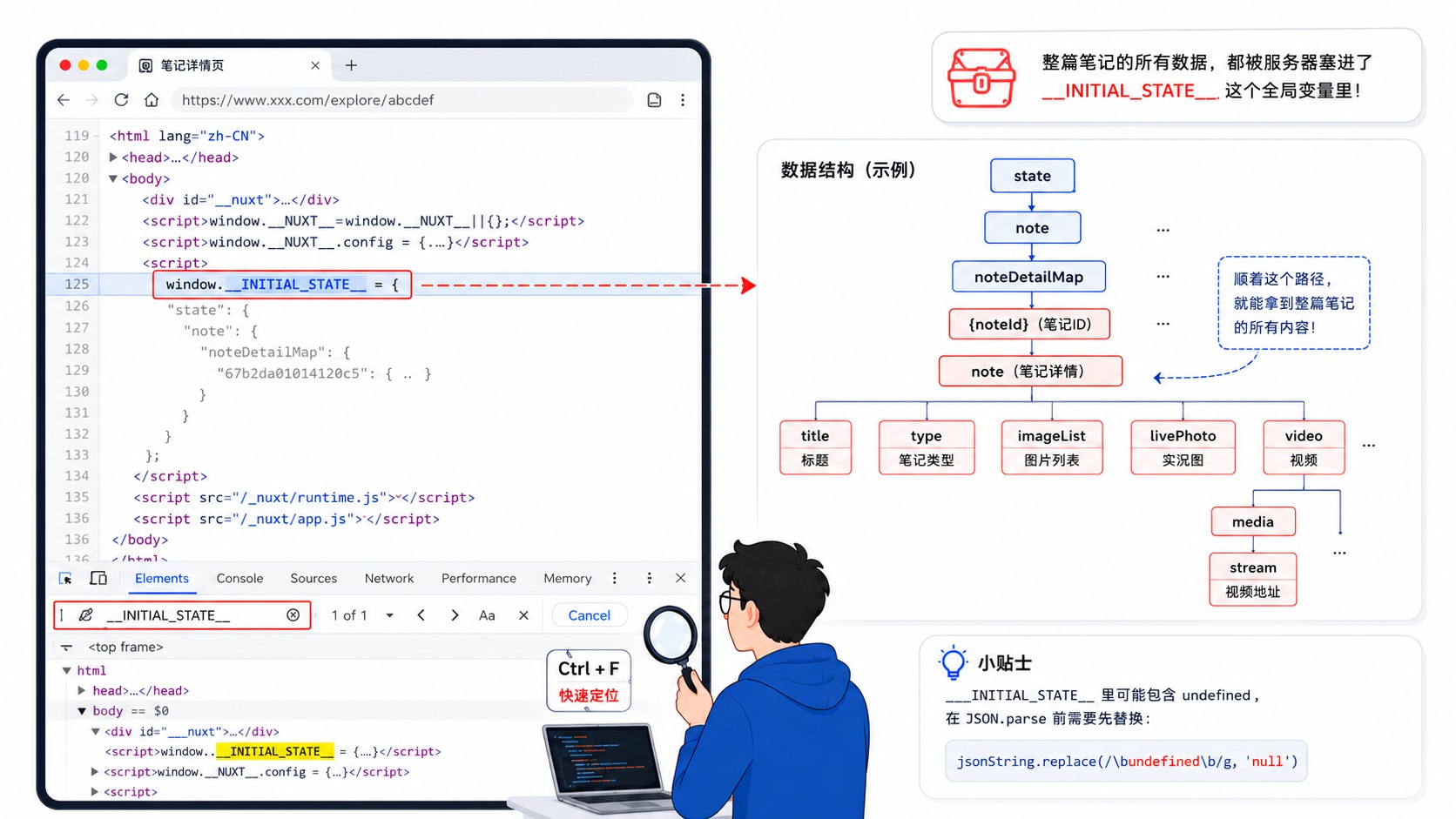
小红书的笔记页面是服务端渲染的(SSR),也就是说页面 HTML 里其实就包含了所有数据。F12 → Elements,Ctrl+F 搜一下 __INITIAL_STATE__,你会找到这么一段:
window.__INITIAL_STATE__ = { ... 一大坨 JSON ... }
这就是宝藏本藏。 笔记的标题、图片列表、视频流地址、实况照片数据……全塞在这个 JSON 里。把它复制出来格式化一下,结构大概是这样的:
state
└── note
└── noteDetailMap
└── {noteId}
└── note
├── title → 笔记标题
├── type → "normal"(图文)或 "video"(视频)
├── imageList[] → 图片数组
│ ├── traceId → 图片唯一标识(关键!)
│ ├── fileId → 备用标识
│ ├── urlDefault → 默认图片地址(带水印)
│ └── livePhoto → 实况照片数据
└── video
└── media.stream
├── h264[] → 视频流(兼容性最好)
├── h265[] → 视频流
└── av1[] → 视频流
不需要 Selenium,不需要 Playwright,一个普通的 HTTP 请求拿到 HTML,用正则把这段 JSON 提出来,json.loads 解析就完事了。
有个小坑要注意:这段 JSON 里偶尔会出现裸的 JavaScript undefined(不是字符串 "undefined"),直接解析会报错,需要先替换成 null。
3. 灵魂一步:用 traceId 拼出无水印原图地址
翻 imageList 里每张图片的字段,会发现一个叫 traceId 的东西。它是什么?它是这张图片在小红书 CDN 上的唯一身份标识。
知道这个 ID 之后,试着拼一个地址:
https://ci.xiaohongshu.com/{traceId}?imageView2/2/format/png
浏览器里打开一看——干干净净的原图,没有任何水印。
原理很简单:ci.xiaohongshu.com 是小红书的 CDN 图片服务,imageView2 是七牛云的图片处理参数,直接请求这个地址拿到的是 CDN 上的源文件,压根不经过水印处理层。
如果 traceId 不存在(少数情况),可以看 fileId 字段,它有时候带路径前缀(比如 spectrum/xxxxxx),取最后一段当 ID 用,效果一样。实在两个都没有,那只能退而求其次用 urlDefault 了(会带水印)。
4. 视频怎么拿?
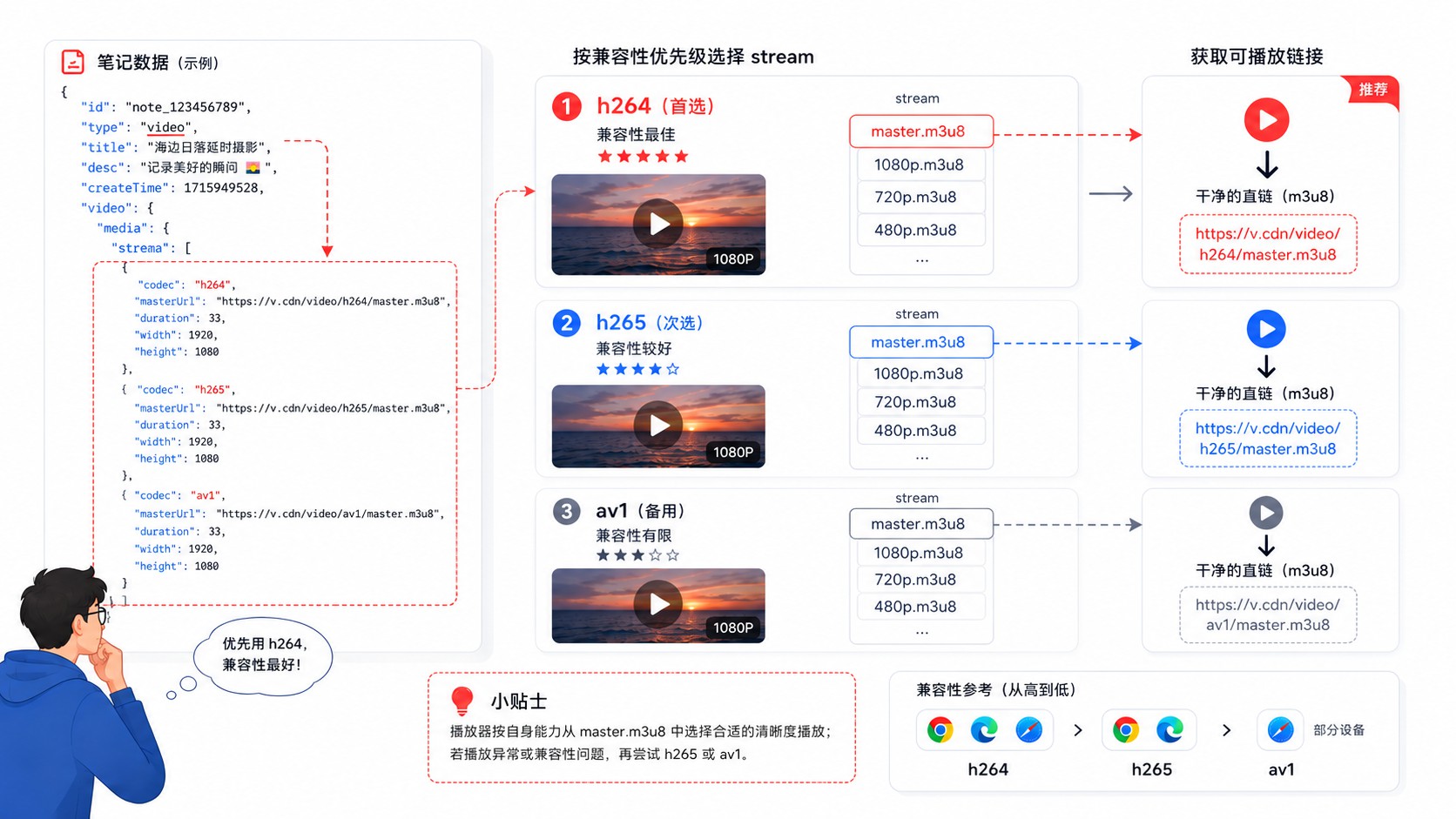
视频类型的笔记,note.type 是 "video",视频流地址在 note.video.media.stream 下面。
这个 stream 按编码格式分了三组:h264、h265、av1,每组是一个数组,数组第一个元素里有个 masterUrl,那就是视频的直链地址。
优先选 h264——兼容性最好,基本所有设备都能播。h265 体积更小但部分老设备不支持,av1 更新但普及度还不够。
拿到 masterUrl 之后直接下载就行,不需要像图片那样绕水印,视频本身就是无水印的。
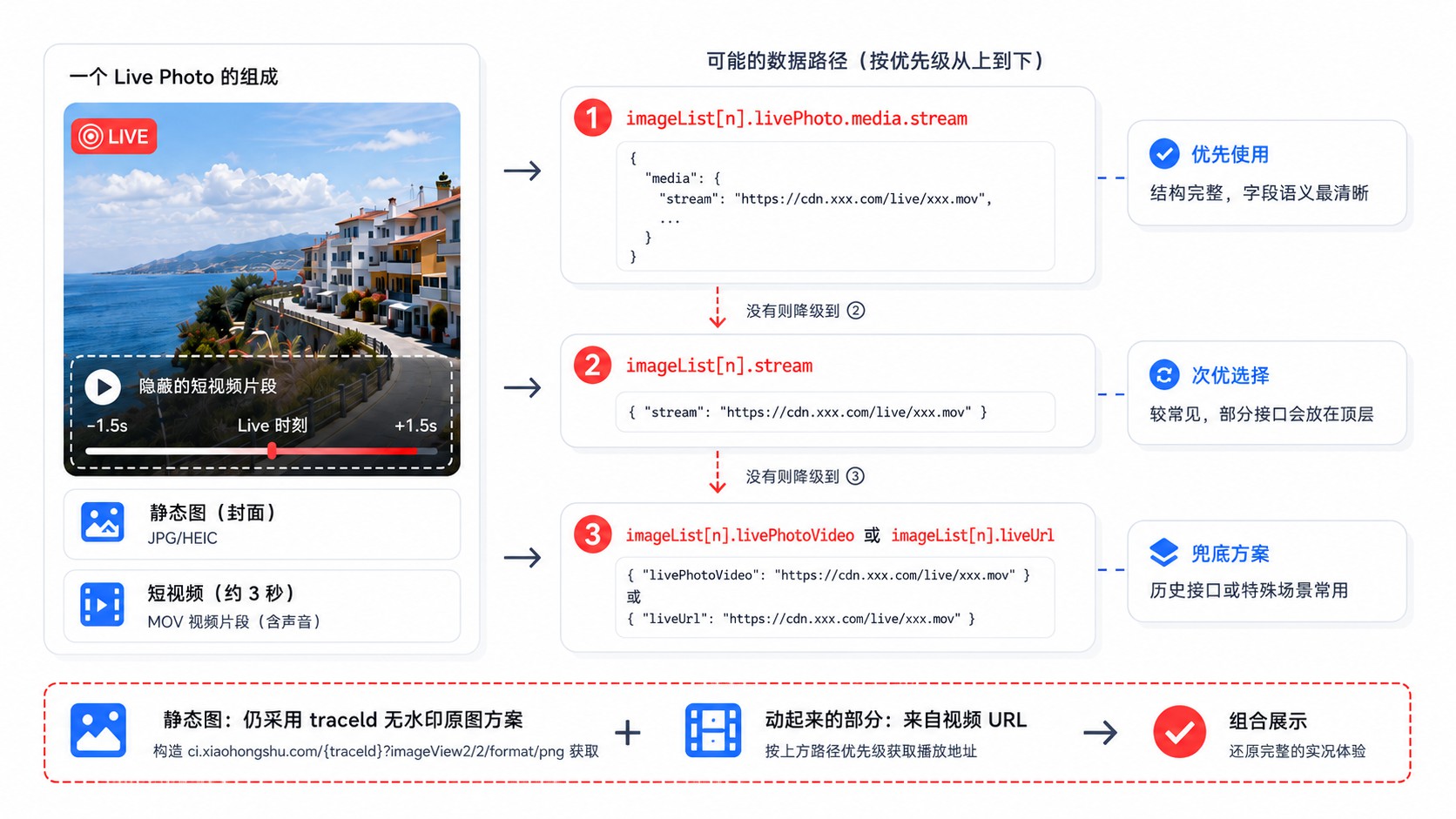
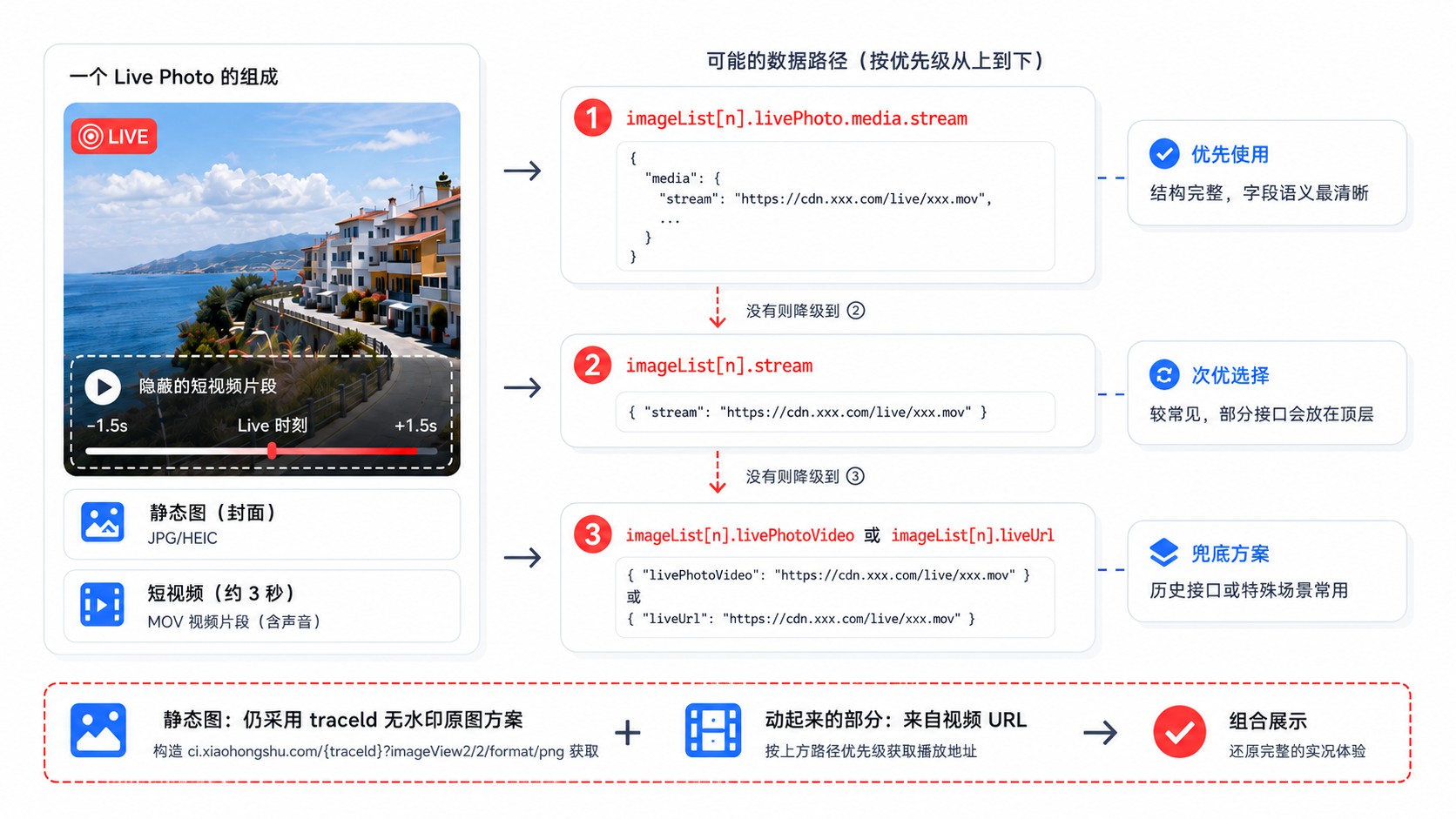
5. 实况照片:最折腾的部分
小红书的实况照片(Live Photo)本质是一张静态图 + 一段短视频。图片的无水印地址用上面的 traceId 方法就能拿到,但实况视频的数据位置,在不同时期的笔记里居然不一样。
我翻了不少笔记,总结出三个可能的位置:
最常见的: imageList[n].livePhoto.media.stream —— 和主视频一样的结构,按编码分组,取 masterUrl。
旧版本: imageList[n].stream —— 直接挂在图片对象的顶层,不在 livePhoto 下面。
兜底字段: imageList[n].livePhotoVideo 或 imageList[n].liveUrl —— 有些笔记会把实况视频的 URL 直接扔在这些字段里,没有嵌套结构。
做的时候按优先级依次检查这三个位置,命中一个就用一个。这样不管是新笔记还是老笔记,都能正确提取。
6. 分享链接的处理
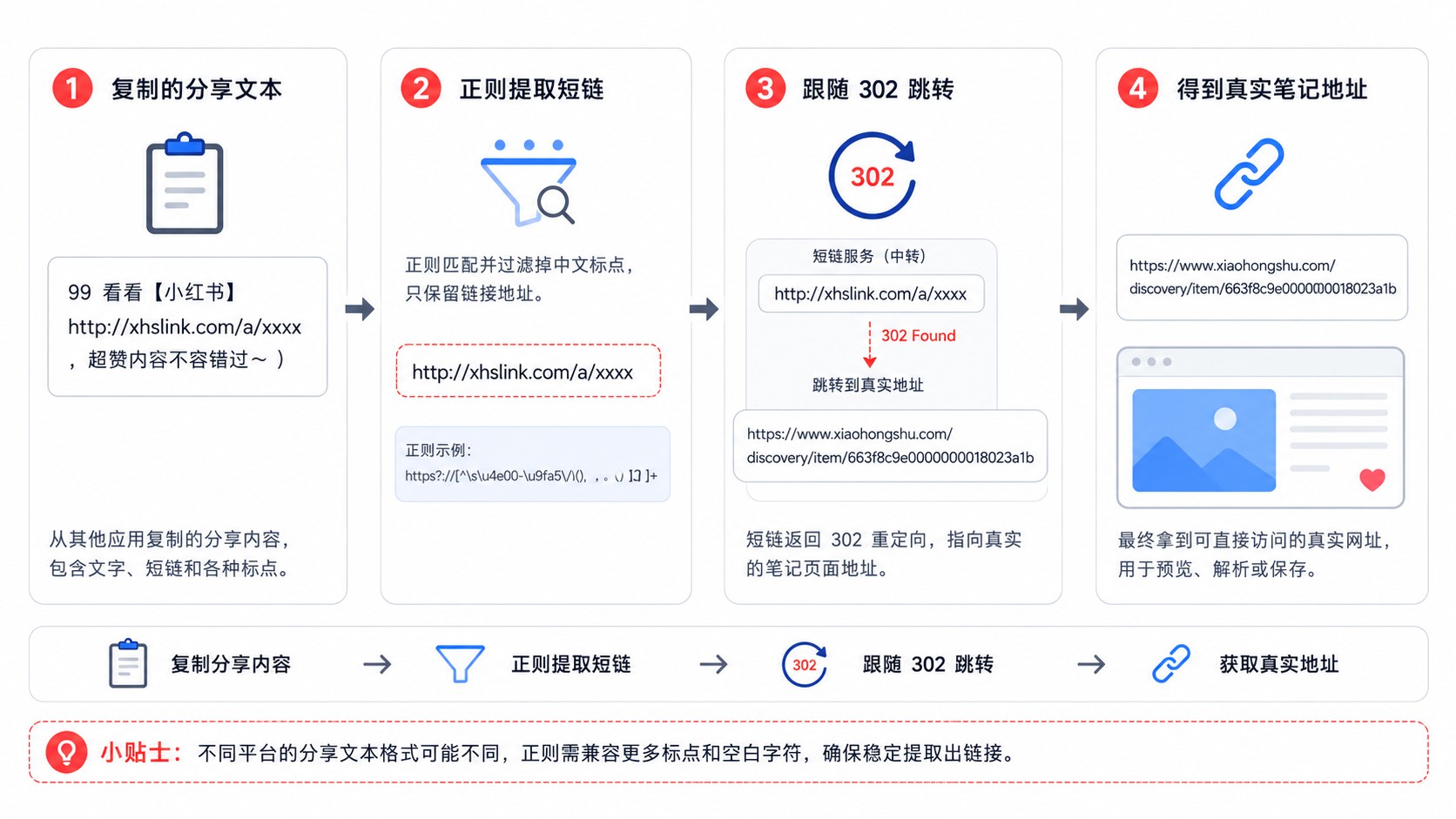
从 App 里复制出来的分享文本通常长这样:
99 看看【小红书】 http://xhslink.com/a/xxxx
两个问题要处理:一是链接被夹在中文文本里,要用正则提取出来(注意排除中文标点 ,)】,小红书分享文本很爱在链接后面紧跟这些);二是 xhslink.com 是短链,需要跟一次 302 跳转才能拿到真实的笔记 URL。
这一步没啥技术含量,但不做的话后面全白搭。
7. 做成工具时的几个设计决策
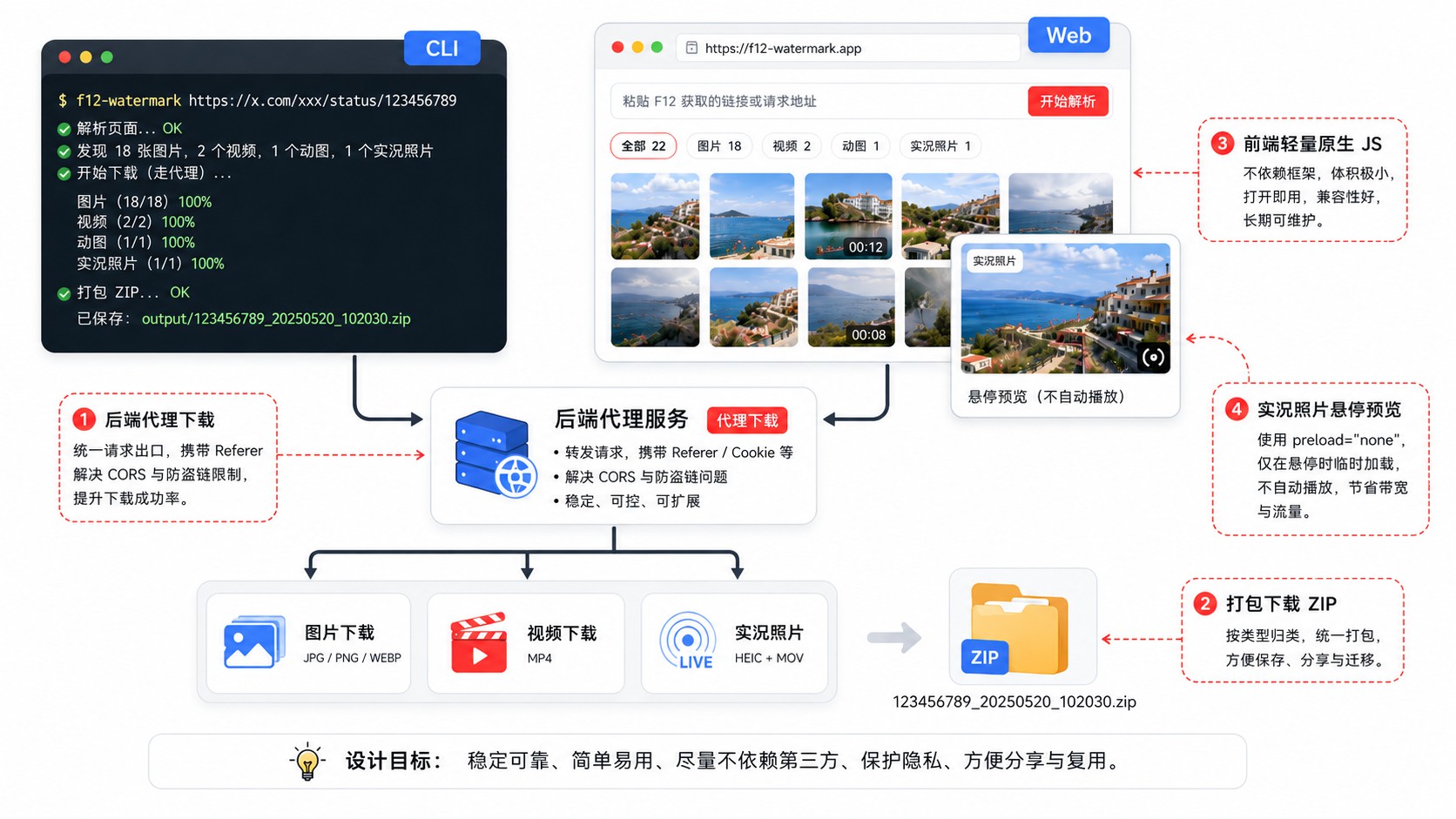
思路通了之后,实现其实很直接。我最后做成了 CLI + Web 双模式,聊几个值得一提的决策:
为什么需要后端代理下载? 小红书的 CDN 有 Referer 和 CORS 限制,前端直接请求图片地址会被拒。所以 Web 版做了一个后端代理接口,用服务端帮用户去请求资源再转发回来。顺便用 RFC 5987 编码解决了中文文件名的下载问题。
为什么做打包下载? 一篇笔记可能有十几张图,逐张点下载太累。做了个接口把所有图片、实况视频、主视频一次性打包成 zip,点一下全搞定。
为什么前端不用框架? 这就是个工具页面,一个输入框 + 一个图片网格 + 几个按钮,用 React/Vue 纯属大炮打蚊子。原生 JS 写下来也就一百多行,改完刷新就能看效果,没有构建步骤。
实况照片的交互怎么做的? 图片网格里,实况图右上角有个红色 LIVE 角标。鼠标悬停时,在图片上方叠加一个隐藏的 <video> 元素并播放,移开时暂停重置。CSS 用 position: absolute + opacity 控制显隐。关键是 preload="none"——不加的话页面一加载就会开始下载所有实况视频,流量直接起飞。
8. 踩过的坑
undefined 替换的误伤: 简单的字符串替换 replace("undefined", "null") 在大多数时候没问题,但如果笔记正文恰好包含 “undefined” 这个词就会被殃及。更稳妥的做法是加词边界限制,只替换独立的 undefined 而不是字符串中间的。
需要登录才能看的笔记: 部分笔记(比如仅关注可见的)页面里根本不会渲染 __INITIAL_STATE__,只会返回一个空壳页面。要支持这类笔记,需要在请求时带上登录后的 Cookie。
打包下载的内存问题: 如果把所有资源先下载到内存再打包 zip,碰上图片多或视频大的笔记,内存占用会很夸张。个人本地用无所谓,公开部署的话需要改成流式写入临时文件。
安全风险: 如果下载代理接口接受任意 URL,部署到公网后攻击者可以利用它去请求内网地址(SSRF)。生产环境必须加 URL 白名单,只放行小红书相关的域名。

最后
整个工具的核心思路总结起来就一句话:小红书的水印不在原图上,而是在请求链路中间加的——找到原图的 CDN 直链,水印自然就没了。
至于怎么找到这个直链,靠的就是 F12 + 耐心翻数据结构。技术上没有任何黑魔法,就是观察、分析、试错。
小红书图片下载,小红书无水印,小红书去水印,小红书原图下载,小红书视频下载,小红书实况照片下载,xhscdn水印原理,traceId无水印,ci.xiaohongshu.com,INITIAL_STATE,小红书逆向,F12抓包,小红书CDN直链,小红书图片解析工具